Materials Science Artificial Intelligence (AI) Project Supports Data Service Initiative
Argonne National Lab
The Data Science and Learning Division (DSL) at Argonne National Laboratory tackles advanced scientific problems where data analysis and artificial intelligence can provide critical insights and accelerate discovery.
A primary thrust of the division is to build cross-cutting capability at Argonne to tackle advanced scientific problems where data analysis and artificial intelligence (AI) are key problem solving strategies. Argonne projects produce data of great scientific value, from explorations into renewable energy and global climate change, to cutting-edge research to bolster the fight against cancer. The more easily this data can be analyzed by various analysis services, the more useful it is for the researchers who rely on it to drive discovery.
So DSL scientists have undertaken a project to develop a lab service for interactive, scalable, reproducible data science, leveraging machine learning methods to reduce simulation costs and increase data quality and value for researchers.
As a testbed for developing this service, project leaders collaborated with the Argonne Leadership Computing Facility (ALCF), Materials Data Facility (MDF) team in Argonne’s Physical Sciences and Engineering Division, and with the Globus team, in a project leveraging machine learning to improve model development.
Challenge: Computing stopping power in materials science
Materials scientists are key users of leadership class computing; their studies are critical to improving economic security and competitiveness, national security and human welfare. Finding and understanding new materials is complex, expensive, and time consuming, often taking over 20 years for research to make its way from experiment to industrial application. To accelerate this process, researchers and facilities are motivated to work together to develop data platforms and tools that are accessible to a broad set of scientific researchers.
The Materials Data Facility (MDF) is one project that supports this research collaboration goal by offering a scalable repository where materials scientists can publish, preserve, and share research data; MDF provides a focal point for the materials community, enabling publication and discovery of materials data of all sizes.

One key MDF project focused on understanding and modeling “stopping power,” defined as a “drag” force experienced by high speed protons, electrons, or positrons in a material. Stopping power has applications in areas like nuclear reactor safety, solar cell surface adsorption, and proton therapy cancer treatment. It is also critical to understanding material radiation damage.
Time-dependent density functional theory (TD-DFT) offers a great way to compute stopping power: it is highly parallelizable, parameter-free, and can accurately reproduce experimentally-measured stopping powers. However, TF-DFT computations and expensive, and scientists increasingly need to easily access stopping power for many different types of materials in all possible directions, and even ascertain the effects of defects on the stopping power. Thus, DSL researchers are using machine learning to extend TD-DFT’s capabilities.
Solution: Apply Machine Learning to improve model development
DSL scientists set out to use machine learning to create surrogate models for TD-DFT using resources at ALCF. They first defined the model inputs and outputs, then built the model via a process of data Collection, Processing, Representation and Learning:
- First, they collected raw data for training the model – these data, originally generated on Mira by Prof. André Schleife from UIUC, were retrieved from the Materials Data Facility (MDF)
- Next, they processed those raw data to define a training set (a set of input+desired output pairs), using the ALCF Cooley system and the Parsl scripting library
- Finally, they translated the training set data into a form compatible with machine learning: a list of finite-length vectors that each have the same length. (i.e., they selected a representation – see below)
- Lastly, they employed machine learning to find a function that maps the representation to the outputs (the classic supervised machine learning problem)

In machine learning, a data representation is a combination of key variables believed to best correlate with what is trying to be modeled. If your model is meant to differentiate between cats and dogs, for example, one variable in your representation could be “y/n: it barks.”
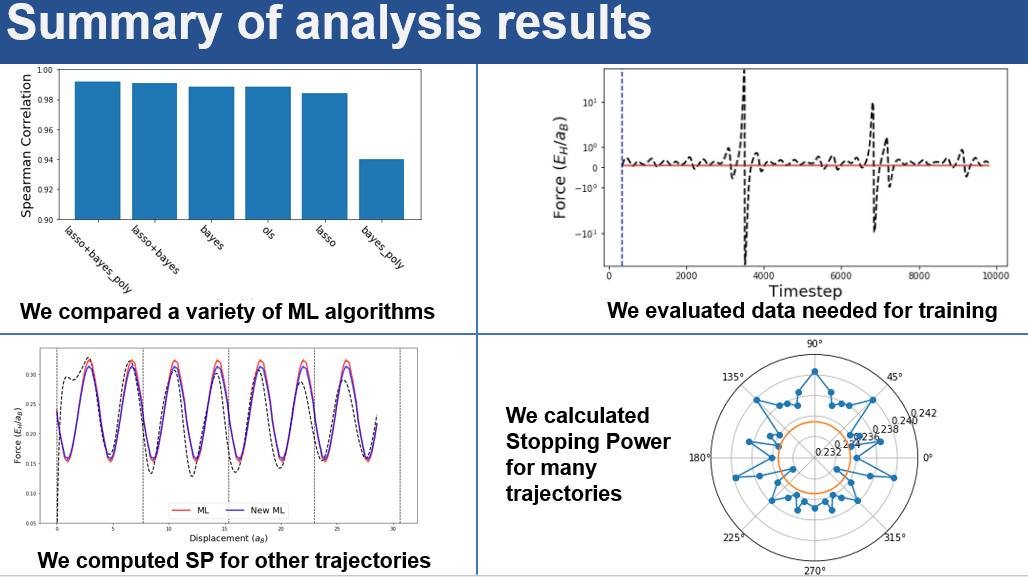
Scientists selected a representation for their data in this project by determining what ‘atomic structure’ actually means in terms of inputs to the model (e.g., what determines force on a projectile, and how does one quantify the effect of this force?). They then trained a machine learning algorithm, selecting an algorithm based on the key criterion of highest prediction accuracy as well as feasibility to train with >104 entries, speed of evaluation, and ability to produce a differentiable model.
To identify the best model, the scientists followed a simple and common procedure: first identifying suitable algorithms (linear models and neural networks in this case), then testing using cross-validation and validating using data outside the original training set.
To facilitate this pipeline using the Globus Platform, scientists first built a search index using Globus Search and MDF capabilities, and populated it with simulation details (e.g., the particle energy) and pointers to the underlying data files on the Petrel Globus endpoint at ALCF. The researchers then used Globus Search functionality embedded in a custom data portal to assemble the data and stage the data from Petrel to the ALCF Cooley resource for computing using Globus Transfer. Finally, a series of Jupyter notebooks running on ALCF’s Jupyterhub instance were used for building the models and for interactive exploration of the data. During this phase, computation-intensive jobs were sent as parallel tasks to Cooley using the Parsl parallel Python scripting library.
Throughout the pipeline, Globus Auth and other Globus platform APIs were used to simplify data access, staging, discovery, synthesis, and movement.
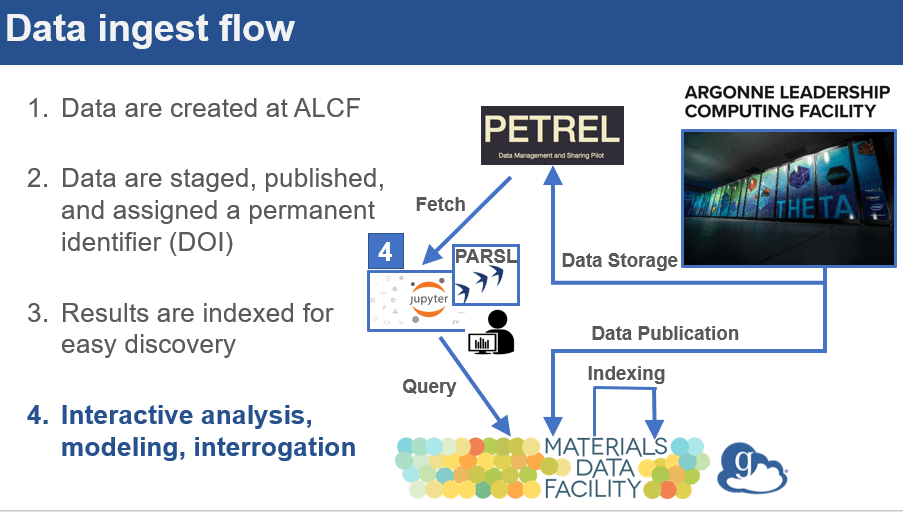
Outcomes
Thanks to this project, Argonne’s DSL has created a surrogate model interactively using ALCF data service capabilities leveraging MDF and the Globus platform, with the original results extended to model stopping power direction dependence in Aluminum.
In addition, Argonne scientists now have an index for heterogeneous distributed data that supports simplified deep learning against these data.
Benefits include:
Simplified interfaces for data publication regardless of data size, type, and location Automation capabilities to capture data from simulation pipelines APIs to foster community development and integration Encouragement of data re-use and sharing Support for Open Science in materials research
Quotes
-
Data science and learning applications require interactivity, scalability and reproducibility -- we need services like Globus authentication built in that streamline rather than complicate the data analysis process."
-
This project was an opportunity to bring together core Globus services (e.g., Auth, Search, Publish, and Transfer) with new tools like Parsl, open source machine learning codes, and high performance computing capabilities at ALCF."
-
The Globus services eliminated a lot of the routine tasks that slow down actually doing the science. I know it takes time to move data between locations, but it’s great to just click a button and be sent to your Jupyter notebook when the data’s there. It’s like ordering off the menu and waiting for your food to arrive, rather than cooking it yourself. This way you can do other things in between."
-
It was reassuring to have the original data files hosted in a persistent repository and replicated to the Workspace when needed. The replication and staging process is invisible, and keeps me from worrying about where the data is and if it’s accessible."
-
DSL [Argonne's Data Science and Learning Division] is interested in finding ways to capture the unique data that’s generated at ALCF, not only in materials science but also in fields as diverse as cosmology, fluid dynamics, catalysis, manufacturing, and high energy physics. MDF is working with ALCF to collect and index these data in a way that makes them discoverable and reusable, and collocates them with machine learning and analysis tools."